
Introduction
Large Language Models (LLMs) have revolutionized our ability to use natural language for complex tasks. By employing best practices such as crafting clear and specific prompts, breaking down tasks, and utilizing prompt engineering techniques like few-shot prompting, we have learned how to improve both the quality and reliability of their outputs.
However, it's important to recognize that LLMs, at their core, are designed to predict the next word (or token). Their training on vast amounts of internet-scale data enables them to identify real-world patterns. Further, instruction-based fine-tuning helps them follow instructions. Despite these advancements, LLMs inherently lack the ability to reason—encompassing problem-solving, decision-making, and critical thinking—on their own. Yet, they "hallucinate" and respond with incorrect answers confidently in certain cases.
Observations show that while LLMs, being next-word predictors, don't show reasoning capabilities, certain prompt engineering techniques can effectively coax out this capability. Through these advanced methods, we can extend the functionality of LLMs beyond simple instruction-following to include more complex forms of reasoning.
We will cover the following advanced prompt engineering techniques in this article:
- Chain-of-Thought Prompting (CoT Prompting)
- Generated Knowledge Prompting
- Least to Most Prompting
- Tree of Thought Prompting (ToT Prompting)
- Chain-of-Verification (CoVe) Prompting
Chain-of-Thought Prompting (CoT Prompting)
Manual CoT Prompting
In our previous discussions on few-shot prompting, we introduced the model to examples that paired a question with its answer. Chain-of-Thought (CoT) prompting takes this a step further. We not only provide the model with the question-answer pairs but also include the intermediate reasoning steps that lead to the answer. This approach encourages the model to mimic this reasoning process, which can enhance its problem-solving capabilities.
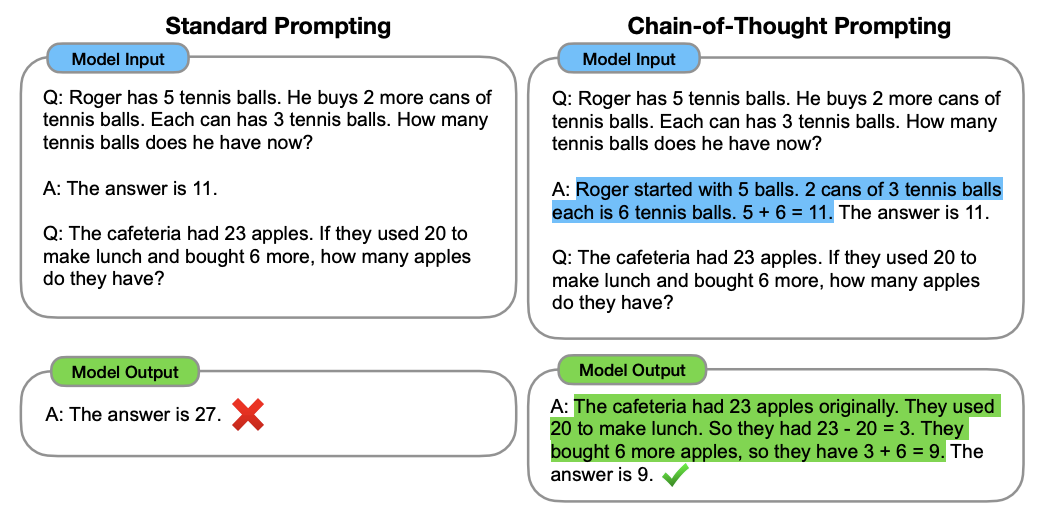
For instance, the image on the left illustrates standard few-shot prompting, while the one on the right showcases CoT prompting.
This technique, also referred to as manual CoT or few-shot CoT, involves manually inputting the reasoning steps in the examples.
Paper Link: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Zero-Shot CoT Prompting
Few-shot CoT has been instrumental in eliciting complex, multi-step reasoning in LLMs. Building on this, researchers have shown that LLMs can also exhibit sound reasoning with zero-shot CoT examples, by simply prompting the model with a cue like "Let's think step by step" before providing an answer.

Paper Link: Large Language Models are Zero-Shot Reasoners
Self-Consistency CoT
Building on the CoT framework, Self-Consistency CoT prompts the language model to produce not just one, but several reasoning paths for a given question. Then, it aggregates these various paths to find the most consistent answer.
For example, when solving a math problem, the model generates different arithmetic sequences and compares them, selecting the most common result as the final answer. This method mirrors a kind of cross-verification process we often use in our own decision-making, ensuring our solutions are not just a fluke but are verified by repeated logical conclusions.
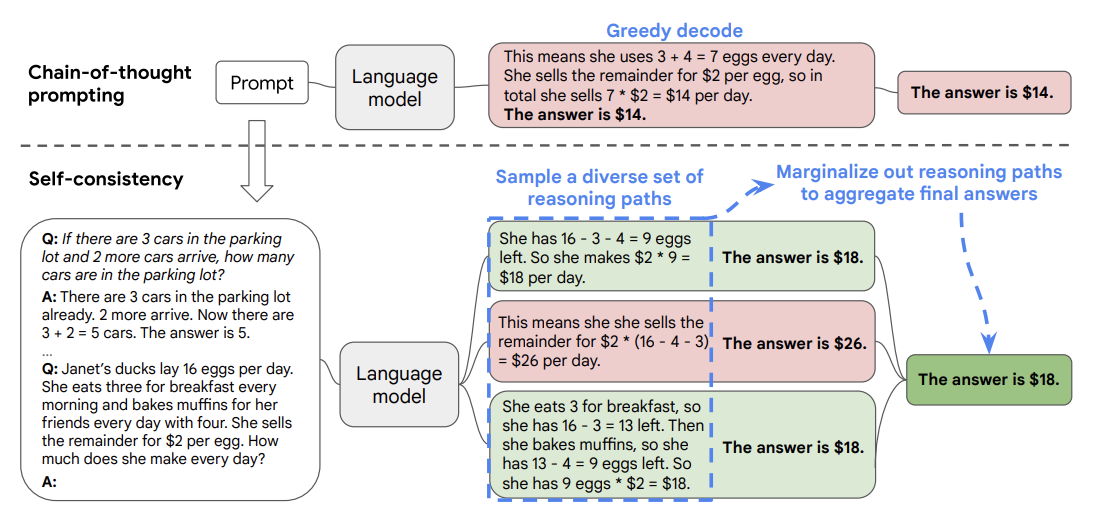
By employing Self-Consistency CoT, we can harness the model's diverse cognitive abilities to enhance the reliability of its output, as demonstrated in the attached image where various reasoning paths about selling eggs lead to a single, consistent answer.
Paper Link: Self-Consistency Improves Chain of Thought Reasoning in Language Models
Multimodal CoT Prompting
While most CoT research has focused on text input, the study Multimodal Chain-of-Thought Reasoning in Language Models extends the technique to multimodal inputs, including both text and images. The model is prompted to provide a rationale before the final answer, based on both the text prompt and visual information.
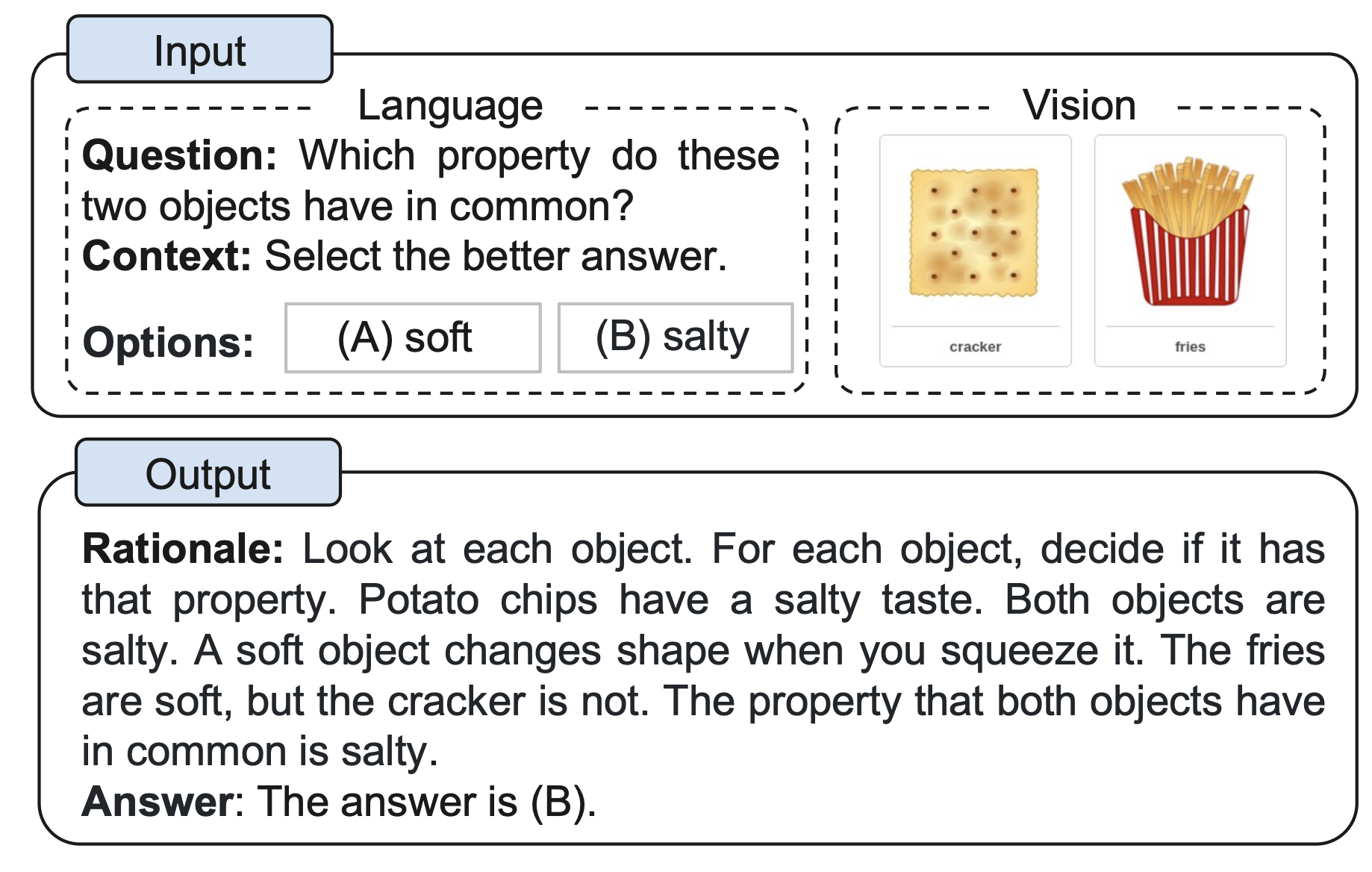
Paper Link: Multimodal Chain-of-Thought Reasoning in Language Models
Generated Knowledge Prompting
Generated Knowledge Prompting (GKP) is an advanced technique that enhances the model's commonsense reasoning abilities by first eliciting relevant knowledge from the model itself and then using this knowledge to inform its responses to questions. Unlike methods that rely on structured knowledge bases or task-specific supervision, GKP generates knowledge dynamically, leveraging the model's pre-existing capabilities to improve its performance across various reasoning tasks.
Here's how it works: the model generates knowledge statements in response to a given question, which are then fed back into the model as additional context when it answers the question. This process has been shown to boost the performance of LLMs significantly.
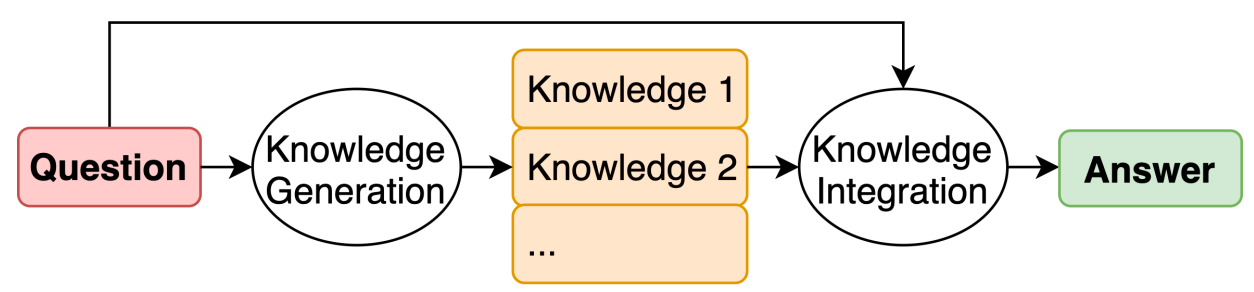
By implementing GKP, we're not just asking the model to answer questions; we're guiding it to first 'think out loud' about what it knows related to the question, then use that self-generated knowledge to come up with an answer. This self-referential method aligns with how we often solve problems by drawing on our internal knowledge before making decisions, underscoring the growing sophistication of LLMs in mimicking human cognitive processes.
We can also use this along with Self-consistency to generate multiple knowledge statements and based on the majority, choose the correct answer.
Paper Link: Generated Knowledge Prompting for Commonsense Reasoning
Least to Most Prompting
Least to Most Prompting involves a top-down problem decomposition followed by bottom-up resolution generation. By breaking down problems into simpler subproblems and solving them in sequence, this approach mirrors the human method of problem-solving where understanding how to decompose a complex problem effectively equates to solving it.
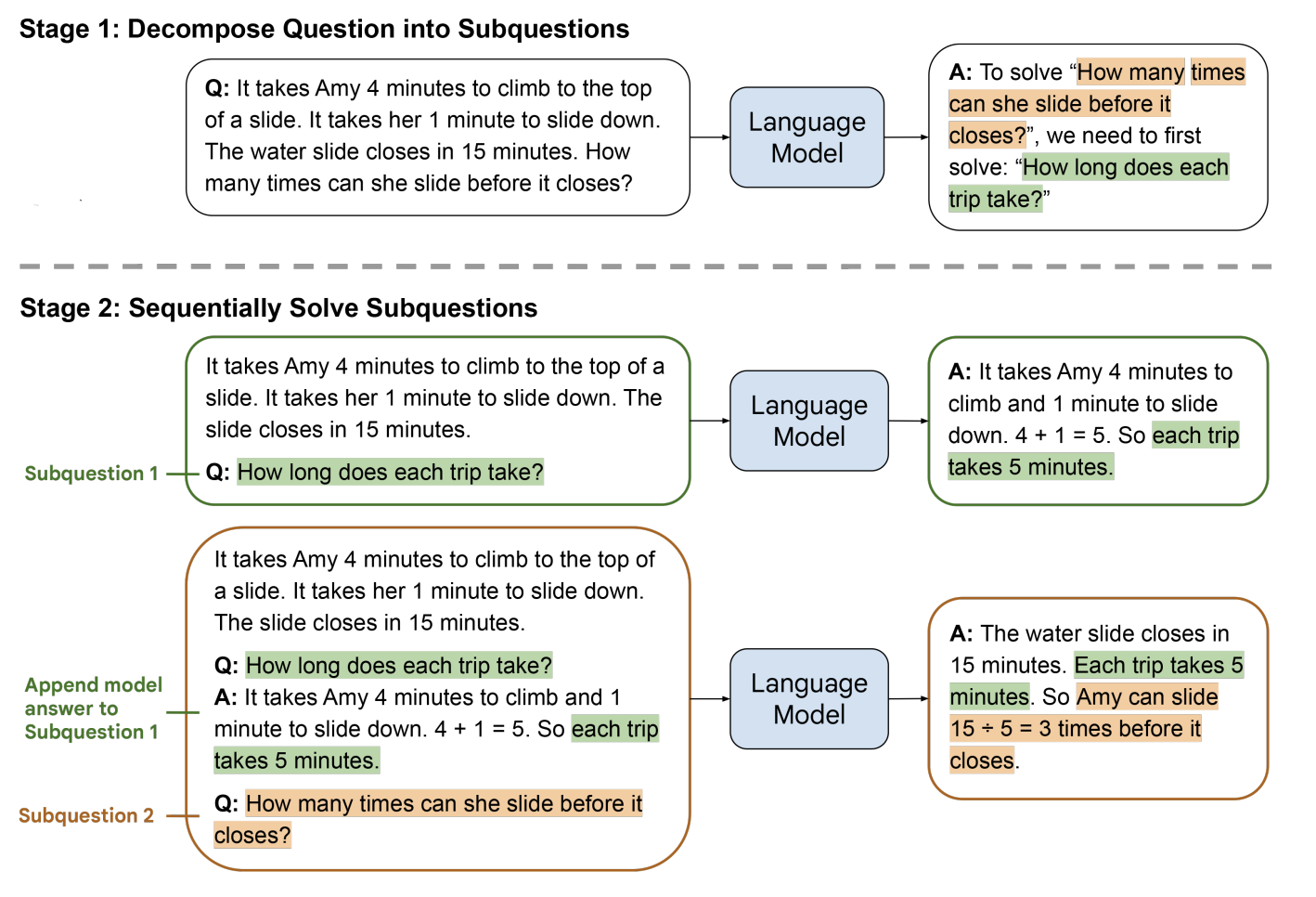
For instance, consider a math problem where Elsa has 5 apples and Anna has 2 more apples than Elsa. The question asks how many apples they have together. The Least to Most Prompting technique would first ask the model to break down the problem into subproblems: determining the number of apples Anna has and then calculating the total. The model would solve these sequentially: Anna has 2 + 5 = 7 apples, then Elsa and Anna together have 5 + 7 = 12 apples.
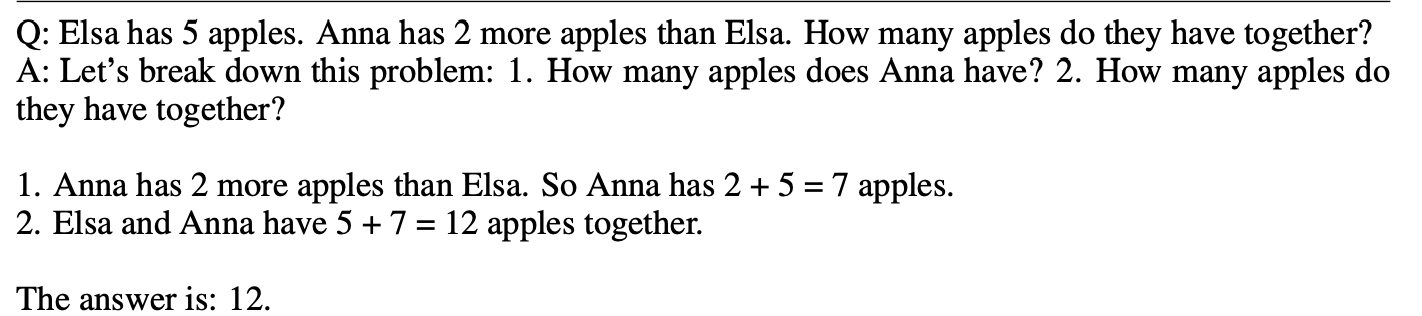
This technique has been shown to improve upon chain-of-thought prompting, especially for problems requiring five or more steps to solve.
Paper Link: Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Tree of Thought Prompting (ToT Prompting)
Building upon the Chain of Thought framework, Tree of Thought (ToT) Prompting introduces a more sophisticated method for language models to solve problems. ToT transforms the problem-solving process into a tree structure, where each "node" represents a potential solution or partial answer. This allows the model to explore different "branches" or reasoning pathways before concluding.
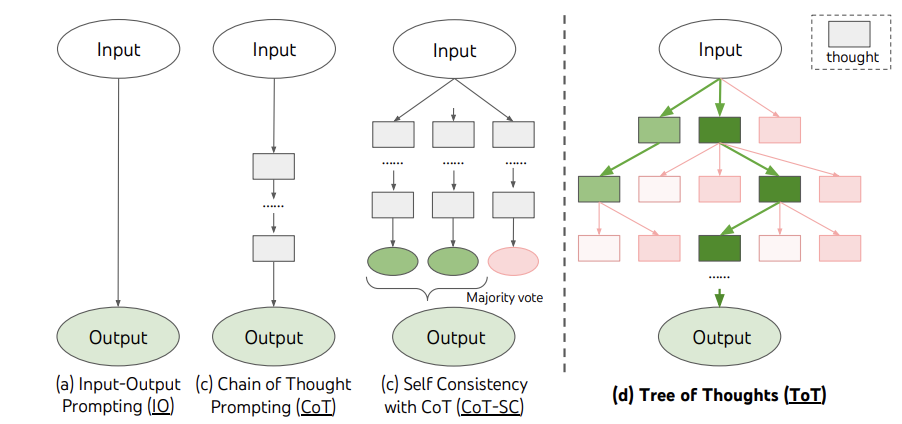
The key to ToT is its non-linear approach to decision-making, enabling the model to look ahead or backtrack as needed. This mirrors human problem-solving, where we often consider multiple options and outcomes before deciding on the best course of action.
For example, in games or puzzles that require strategic planning, ToT has been shown to greatly improve the problem-solving performance of language models compared to linear methods like CoT, enhancing their ability to handle complex tasks with multiple steps.

Paper Link: Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Chain-of-Verification (CoVe) Prompting
The Chain-of-Verification (CoVe) is a strategic prompting method designed to enhance the accuracy and reliability of language model outputs by incorporating a self-verification mechanism.
This technique consists of four principal stages:
- Generate Baseline Response : Initially, the model produces a response to the query without any specific verification strategy.
- Plan Verifications : Subsequently, the model generates a series of verification questions based on the initial query and its baseline response. These questions are aimed at identifying potential errors in the original answer.
- Execute Verifications : The model then proceeds to answer the verification questions it generated, checking these answers against the original response to detect inconsistencies or mistakes.
- Generate Final Verified Response : If any inconsistencies are discovered, the model crafts a revised response that integrates the results of the verification process.

This approach is particularly effective because it prompts the same language model to engage in different types of reasoning to achieve the desired outcome. It resembles a feedback loop where the model acts as both the creator and the critic of its content, similar to a human expert who critically reviews their work for accuracy.
Paper Link: Chain-of-Verification Reduces Hallucination in Large Language Models
Conclusion
As we wrap up, it's clear that the right prompts can lead large language models to impressive feats of reasoning. From the careful breakdowns of Chain-of-Thought (CoT) to the strategic verifications of CoVe, these techniques aren't just about getting the right answers—they're about the models understanding the paths to those answers.
The idea of using "how humans think and learn" to make the LLMs reason has pushed researchers to find many more innovative techniques that have not been covered in this article. We will try to cover them in future articles and guides.
References
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Large Language Models are Zero-Shot Reasoners
- Self-Consistency Improves Chain of Thought Reasoning in Language Models
- Multimodal Chain-of-Thought Reasoning in Language Models
- Generated Knowledge Prompting for Commonsense Reasoning
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- Chain-of-Verification Reduces Hallucination in Large Language Models
All images are taken from the papers mentioned in the respective sections of the article.