
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is a strategy that boosts the capabilities of large language models (LLMs). It does so by adding data from trustworthy knowledge base as context alongwith the prompt.
RAG is particularly useful for time-sensitive or domain-specific usecases where retraining the model is not feasible. RAG is a cost-effective way to enhance the performance of LLMs without requiring retraining.
It can be used to create applications that require the model to be grounded in facts and proprietary data. Examples of such applications include conversational agents, question answering systems, and chatbots.
Few popular RAG-based products are:
- ChatGPT (with web search)
- Perplexity
- Chat with PDF/Youtube products
- AI Support Chatbot products
- Ask questions over Internal Knowledge Base products
To put it simply, Retrieval Augmented Generation as the name suggests, retrieves relevant context, adds it to the prompt and then generates a response based on the retrieved context.

Why do we need RAG?
While prompt engineering can help LLMs generate good responses, LLMs often hallucinate and confidently answer incorrectly. There could be multiple reasons for this:
- LLMs have a cutoff date (frozen in time) and the model has no context of recent events.
- The state-of-the-art (SOTA) LLMs are general-purpose models and lack domain-specific knowledge.
- Certain applications require access to private/propietary data which the model does not have.
- When LLMs answer a question, it does not know about the source of the information because of how the architecture works.
RAG can help address these issues by providing the model with context from a knowledge base. This can help increase the reliability of the model and make it more useful for domain-specific applications. LLMs are good at understanding and replying in natural language. If we provide it context, it can answer fairly complex user queries. RAG can also help the model cite the sources of the information it is providing, making it more transparent and trustworthy.
How does RAG work?
RAG involves two major steps:
- Retrieval of relevant context
- Generating a response to the user's query based on the retrieved context
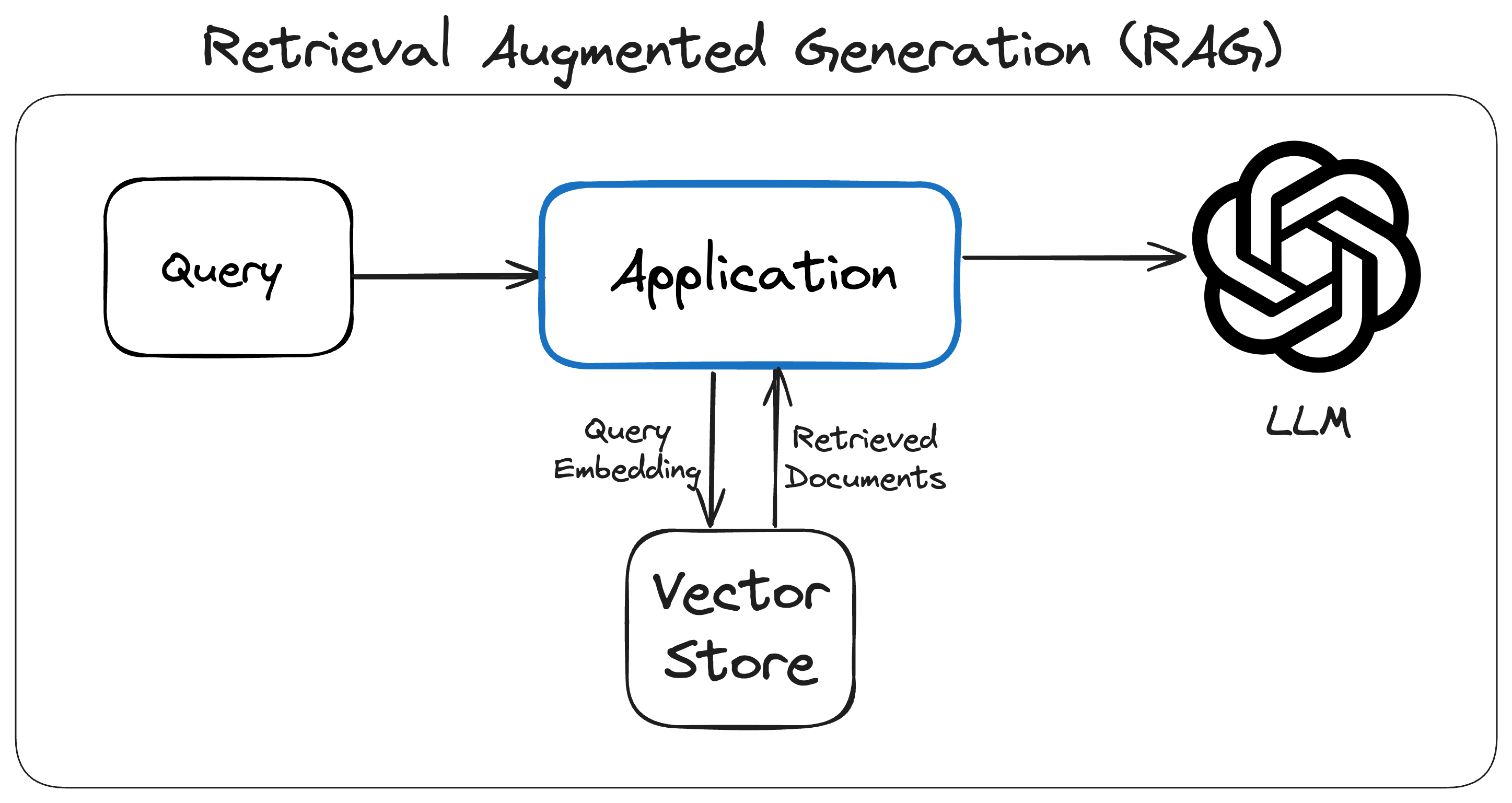
Let's understand these steps in detail:
Retrieval of relevant context
The first step in RAG is to retrieve relevant context based on the user's query. The context helps the LLM generate a good response to the user's query. This context can be retrieved from a knowledge base, a search engine, or any other source of information. The process usually involves searching for relevant documents using vector search in a vector database/store or using keyword search in traditional search databases like Elasticsearch based on the query. Instead of using entire articles, pages, files as context, we usually use only the most relevant snippets usually created during the indexing phase. We will discuss the retrieval process in detail in the RAG Pipeline section.
Generating a response based on the retrieved context
After retrieving the relevant documents, these documents are added to the prompt alongwith the query. It is then sent to the LLM for generating the response.
Example:
Context:
"""
Document 1: "Joseph Robinette Biden Jr. (/ˈbaɪdən/ ⓘ BY-dən; born November 20, 1942) is an American politician who is the 46th and current president of the United States since 2021."
Document 2: "Biden was elected the 46th president of the United States in November 2020. He defeated the incumbent, Donald Trump, becoming the first candidate to defeat a sitting president since Bill Clinton defeated George H. W. Bush in 1992."
Document 3: "The president of the United States is the head of state and head of government of the United States of America."
Document 4: "The president of the United States is elected to a four-year term by the people through the Electoral College."
"""
Based on the above context, answer the following question:
Who is the current president of the United States?
RAG Pipeline
There are three different stages in RAG:
Indexing
The first step in the RAG pipeline is to index the documents that will be used for retrieval. In most RAG pipelines, the documents are indexed in a vector database/store. The documents are chunked based on certain chunking strategies and then converted into vector embeddings using an embedding model like text-embedding-3-small. These embeddings are then stored in in-memory vector stores like Faiss or vector databases like Pinecone.

Retrieval
The retrieval stage involves searching for relevant documents based on the user's query. The query is converted into a vector embedding using the same embedding model used during indexing. This embedding is then used to search for the most relevant documents in the vector database/store. The embedding of the query is compared with the embeddings of the documents to find the most similar documents using different techniques depending on the embedding model used.

Generation
The final stage in the RAG pipeline is to generate a response based on the retrieved context. The retrieved documents are added to the prompt alongwith the user's query and sent to the LLM for generating the response. The LLM generates the response based on the prompt and the context provided.
Example:
Context:
"""
{relevantDocuments}
"""
Based on the above context, answer the following question:
{userQuery}
Improving RAG Performance
Metadata filtering
Filtering the documents based on metadata can help improve the performance of the RAG system. Many vector stores allow metadata filtering which can be used to filter out irrelevant documents or search specifically based on certain parts of the user's query. We can add the metadata to the database in the indexing process either by using existing metadata or generating metadata for each document.
Keyword search
In many usecases, keyword search using traditional search databases like Elasticsearch might be a better choice compared to vector search. In case of keyword search, the query is used to search for relevant documents in the search engine ranked based on BM25, tf–idf or similar metrics.
We will discuss Keyword Search based RAG in detail in further articles.
Hybrid search
Many usecases might benefit from hybrid search which is a combination of vector search and keyword search. In case of hybrid search, the query is used to search for relevant documents in both the vector database/store and the search engine and the scores are combined using some formula to rank the documents.
We will discuss Hybrid Search in detail in further articles.
Reranking
Reranking is an important concept that can be used in the retrieval stage to improve the accuracy of the retrieval. Reranking involves reordering the documents based on a single or multi-stage process to get better results. We will discuss Reranking in detail in further articles.
Advanced Techniques
There are many advanced techniques used in the indexing stage and the retrieval stage to make the retrieval process faster and/or also to increase the accuracy of the retrieval. We will discuss these techniques in further articles.
Conclusion
Retrieval Augmented Generation (RAG) is a powerful technique that we can use to enhance the capabilities of LLMs. By providing the model with context from a knowledge base, RAG helps significantly improve the reliability and accuracy of the model. RAG is particularly useful for domain-specific applications where the model needs to be grounded in facts and proprietary data.
By combining retrieval and generation, RAG can help create applications that require the model to be more transparent and trustworthy. RAG is a cost-effective way to enhance the performance of LLMs without requiring retraining.