
What are Vector Embeddings?
Vector embeddings transform complex, high-dimensional data—like text, images, or audio—into vectors, which are arrays of floating-point numbers. These vectors capture the essence of the data, such as the meaning of a sentence or the content of an image, making it possible for machine learning models to process and analyze the data more efficiently. The process involves mapping high-dimensional data to a lower-dimensional space while preserving the relationships between data points, facilitating operations like similarity search, clustering, and classification.
Vector embeddings are created using embedding models, which are trained on large datasets to learn the relationships between different data points. For example, a text embedding model might be trained on a large corpus of text to learn the meaning of words and sentences, while an image embedding model might be trained on a large dataset of images to learn the content of the images. The distance between two vectors in the embedding space is a measure of their similarity, with similar items having vectors that are close together and dissimilar items having vectors that are far apart.

Vector embeddings are a powerful tool for solving a wide range of AI problems. Here are some of the key use cases where vector embeddings can be applied:
- Semantic Search
- Clustering
- Classification
- Retrieval-Augmented Generation (RAG)
- Recommendations
- Anomaly Detection
We will discuss each of these use cases in more detail in upcoming sections.
How to build applications using vector embeddings?
Building applications using vector embeddings involves several steps, including creating the embeddings of the data, storing the embeddings, and using the embeddings during runtime.
Here's a high-level overview of the process:
- Create vector embeddings: Use an embedding model to create vector embeddings of the data.
- Store vector embeddings: Store the vector embeddings in a vector store, which is a system that allows you to efficiently store and retrieve vector embeddings.
- Retrieving using vector embeddings: Use the vector embeddings during runtime to perform tasks like semantic search, RAG, clustering, classification, and recommendation.
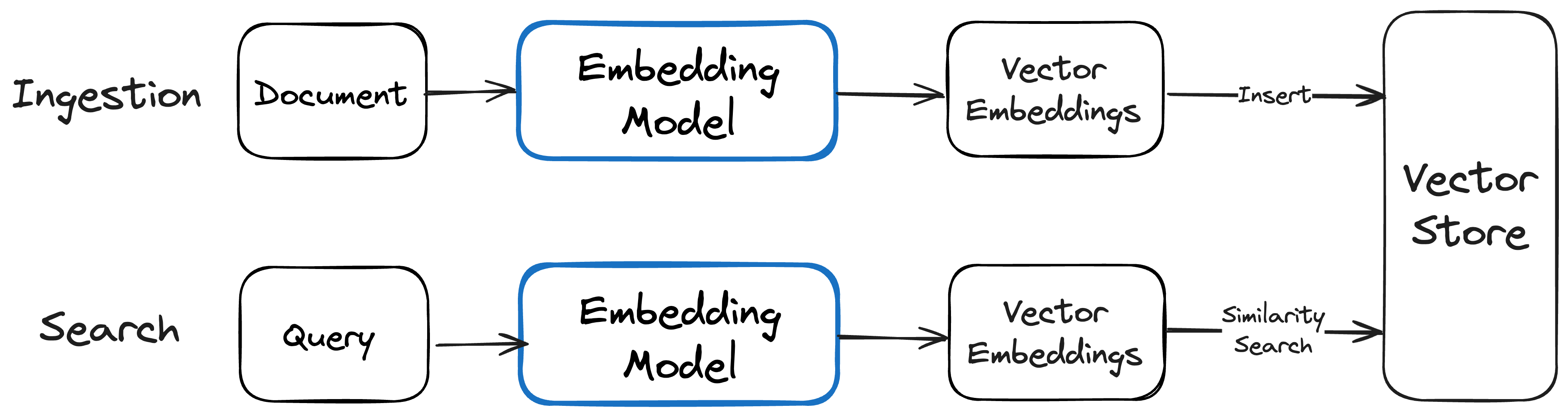
Creating vector embeddings
Creating vector embeddings involves using an embedding model to transform the data into vectors. The process varies depending on the type of data, such as text, images, or audio. For example, to create text embeddings, you would use a text embedding model to transform the text data into vectors, while to create image embeddings, you would use an image embedding model to transform the image data into vectors.
Sample code for creating text embeddings using OpenAI Embeddings:
# Source: https://platform.openai.com/docs/guides/embeddings
from openai import OpenAI
# Initialize the OpenAI client with your API key
client = OpenAI()
def get_embedding(text, model="text-embedding-3-small"):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
print(get_embedding("AGI has been achieved internally"))
Let's look at the best models for creating vector embeddings (as of Feb 2024):
-
Text embeddings: Text embeddings are vector representations of text data, such as words, sentences, or documents. There are several models that are widely used for creating text embeddings, including:
-
Multi-modal embeddings: Multi-modal embeddings are vector representations of multi-modal data, such as text, images, and audio. There are several models that are widely used for creating multi-modal embeddings, including:
Storing embeddings in vector stores
Vector stores are systems that allow you to efficiently store and retrieve vector embeddings. You might think that why not use a traditional database to store vector embeddings? The reason is that traditional databases are not optimized for similarity search and other operations that are common with vector embeddings. Vector stores are designed to efficiently store and retrieve vector embeddings, making them ideal for use in AI applications. There are two main types of vector stores:
- In-memory vector indexes: These are in-memory data structures that allow you to efficiently store and retrieve vector embeddings. Faiss is a popular in-memory vector index.
- Vector databases: These are databases that are designed to efficiently store and retrieve vector embeddings. They differ from in-memory vector indexes in that they can store vector embeddings on disk and provide additional features like indexing, querying, and scaling. Pinecone, Qdrant, MongoDB Atlas Vector Search, Elasticsearch's Vector Database are popular vector databases.
Retrieving using vector embeddings
Using vector embeddings during runtime involves performing tasks like semantic search, RAG, clustering, classification, and recommendation. This typically involves creating vector embeddings of the query or input data using the same embedding model used while ingesting the data, and then using similarity search to find the most relevant items based on the similarity of their vector embeddings.
Similarity between vectors can be measured using various metrics, such as cosine similarity, Euclidean distance, and dot product. These metrics help us understand how similar two vectors are in the embedding space.
Let's briefly discuss each of these metrics:
- Cosine similarity: Measures the cosine of the angle between two vectors. It ranges from -1 to 1, with 1 indicating that the vectors are pointing in the same direction, 0 indicating that the vectors are orthogonal, and -1 indicating that the vectors are pointing in opposite directions. High cosine similarity indicates that the vectors are similar, while low cosine similarity indicates that the vectors are dissimilar.
- Euclidean distance: Measures the straight-line distance between two vectors. It ranges from 0 to infinity, with 0 indicating that the vectors are at the same point, and higher values indicating that the vectors are farther apart. Low Euclidean distance indicates that the vectors are similar, while high Euclidean distance indicates that the vectors are dissimilar.
- Dot product: Measures the projection of one vector onto another. It ranges from -infinity to infinity, with positive values indicating that the vectors are pointing in the same direction, 0 indicating that the vectors are orthogonal, and negative values indicating that the vectors are pointing in opposite directions. High dot product indicates that the vectors are similar, while low dot product indicates that the vectors are dissimilar. It is different from cosine similarity as it does not normalize the vectors.
You can find the right similarity measure for your use case by looking at the documentation of the embedding model you are using.

What use cases can vector embeddings solve?
Semantic Search
Semantic search uses vector embeddings to find items semantically related to a query. For example, in a product search, a user might enter a query like "red dress" and expect to see results that include items depicting a red dress, even if the title does not contain the exact words "red dress". Embeddings allow for such nuanced searches by representing both items and queries in the same vector space, helping find relevant results based on semantic similarity.
Example: Finding products through semantic search
Let's say we have a product catalog and we want to allow users to search for products using natural language queries. We can use vector embeddings to represent the products and the user queries, and then use similarity search to find the most relevant products to the user query. Let's go through the steps to achieve this:
- Create vector embeddings: Use a text embedding model to create vector embeddings of the product descriptions and other relevant text data. You can also use multi-modal embeddings if your product catalog includes images or other types of data.
- Store vector embeddings: Store the vector embeddings in a vector store to efficiently store and retrieve the vector embeddings.
- Use vector embeddings: When a user enters a query, use the same embedding model to create a vector embedding of the query, and then use similarity search to find the most relevant products to the user query. You can use the vector store's similarity search API to do this. The API will return the most relevant products to the user query based on the similarity of their vector embeddings.
Clustering
Clustering is the process of grouping similar items together. For example, customer feedback might be grouped/clustered together to identify common themes or sentiments. Vector embeddings can be used to represent the feedback items, and then we can use clustering algorithms to group together similar items. This can help us identify patterns and trends in the feedback data.
Example: Clustering user feedback to get insights
Let's say we have a large dataset of customer feedback and we want to identify common themes or sentiments in the feedback. We can use vector embeddings to represent the feedback items, and then use clustering algorithms to group together similar items. This will help us identify patterns and trends in the feedback data, such as common themes or sentiments. Let's go through the steps to achieve this:
- Create vector embeddings: Use a text embedding model to create vector embeddings of the customer feedback.
- Use vector embeddings for clustering: Use clustering algorithms like K-means or DBSCAN to group together similar feedback items based on their vector embeddings. This will help us identify common themes or sentiments in the feedback data.
Classification
Classification is the process of assigning a category or label to an item. For example, in a product review sentiment analysis application, we might want to classify reviews as positive, negative, or neutral. Vector embeddings can be used to represent the existing reviews along with their labels, and then after finding similar reviews, we can assign the same label to the new review.
Example: Product Review Sentiment classification
Let's say we have a large dataset of product reviews and we want to classify the reviews as positive, negative, or neutral. We can use vector embeddings to represent the reviews along with their labels, and then use classification algorithms to assign a category or label to each review. This will help us understand the sentiment of the reviews and make data-driven decisions based on the sentiment analysis. Let's go through the steps to achieve this:
- Create vector embeddings: Use a text embedding model to create vector embeddings of the product reviews along with their labels.
- Use vector embeddings for classification: Use classification algorithms like logistic regression or support vector machines to assign a category or label to each review based on their vector embeddings. This will help us understand the sentiment of the reviews and make data-driven decisions based on the sentiment analysis.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a technique that combines retrieval and generation models to produce high-quality responses to queries. In RAG, we use the query to retrieve relevant documents based on their similarity to the query, and then pass the contents of the retrieved documents to a generation model like GPT-4 to produce a response. This is particularly useful when we want to generate responses based on recent events, private data, or other information that is not present in the training data. It also helps reduce hallucinations and improve the relevance of the generated responses.
Example: Question Answering using RAG
Let's say we want to build a question-answering system that can generate responses to user queries based on relevant documents. We can use vector embeddings to represent the documents and the user queries, and then use RAG to retrieve relevant documents based on the similarity to the user query, and then generate a response using a generation model like GPT-4. Let's go through the steps to achieve this:
- Create vector embeddings: Use a text embedding model to create vector embeddings of the documents.
- Store vector embeddings: Store the vector embeddings in a vector store to efficiently store and retrieve the vector embeddings.
- Use vector embeddings for RAG: When a user enters a query, use the same embedding model to create a vector embedding of the query, and then use similarity search to find the most relevant documents to the user query. Then, pass the contents of the retrieved documents as context alongwith the query to a generation model like GPT-4 to produce a response. This will help us generate high-quality responses to user queries based on relevant documents.
Recommendations
Recommendation systems use vector embeddings to represent users, items, and interactions between them. For example, in a news recommendation application, we might want to recommend similar articles to users based on the content of the article they are currently reading. Vector embeddings can be used to represent the articles, and then we can use similarity search to find the most relevant articles to recommend to the user.
Example: Recommendation (Related Articles Section)
Let's say we want to build a recommendation system that can recommend similar articles to users based on the content of the article they are currently reading. We can use vector embeddings to represent the articles, and then use similarity search to find the most relevant articles to recommend to the user. Let's go through the steps to achieve this:
- Create vector embeddings: Use a text embedding model to create vector embeddings of the articles.
- Store vector embeddings: Store the vector embeddings in a vector store to efficiently store and retrieve the vector embeddings.
- Find and store related articles: When an article is created or updated, use the same embedding model to create a vector embedding of the article, and then use similarity search to find the most relevant articles to recommend to the user. Store the related articles in a database to be used for recommendations.
Anomaly Detection
Anomaly detection is the process of identifying items that are significantly different from the rest of the data. For example, in a network security application, we might want to identify network traffic that is anomalous and could indicate a security threat. Vector embeddings can be used to represent the network traffic data, and then we can use anomaly detection algorithms to identify the most anomalous items.
Example: Anomaly Detection in Network Traffic
Let's say we want to build an anomaly detection system that can identify network traffic that is anomalous and could indicate a security threat. We can use vector embeddings to represent the network traffic data, and then use anomaly detection algorithms to identify the most anomalous items. Let's go through the steps to achieve this:
- Create vector embeddings: Use an embedding model to create vector embeddings of the network traffic data.
- Use vector embeddings for anomaly detection: Use anomaly detection algorithms like isolation forests or autoencoders to identify the most anomalous network traffic based on their vector embeddings. This will help us identify network traffic that is anomalous and could indicate a security threat.
Conclusion
Vector embeddings are a powerful tool for solving a wide range of AI problems, including semantic search, clustering, classification, RAG, recommendations, and anomaly detection. They allow us to represent complex, high-dimensional data in a lower-dimensional space, making it possible for machine learning models to process and analyze the data more efficiently. By using vector embeddings, we can build AI applications that are more accurate, efficient, and scalable, and provide better user experiences.