
Note: This article is a summary of a paper on "Searching for Best Practices in Retrieval-Augmented Generation" by Wang et al.
Introduction
Generative large language models (LLMs) are prone to generating outdated information or fabricating facts. Retrieval-Augmented Generation (RAG) techniques combine the strengths of pretraining and retrieval-based models to mitigate these issues, enhancing model performance.
By integrating relevant, up-to-date information, RAG improves the accuracy and reliability of responses. Additionally, RAG enables rapid deployment of applications without the need to update model parameters, provided that query-related documents are available.
This article delves into optimal practices for RAG, aiming to balance performance and efficiency.
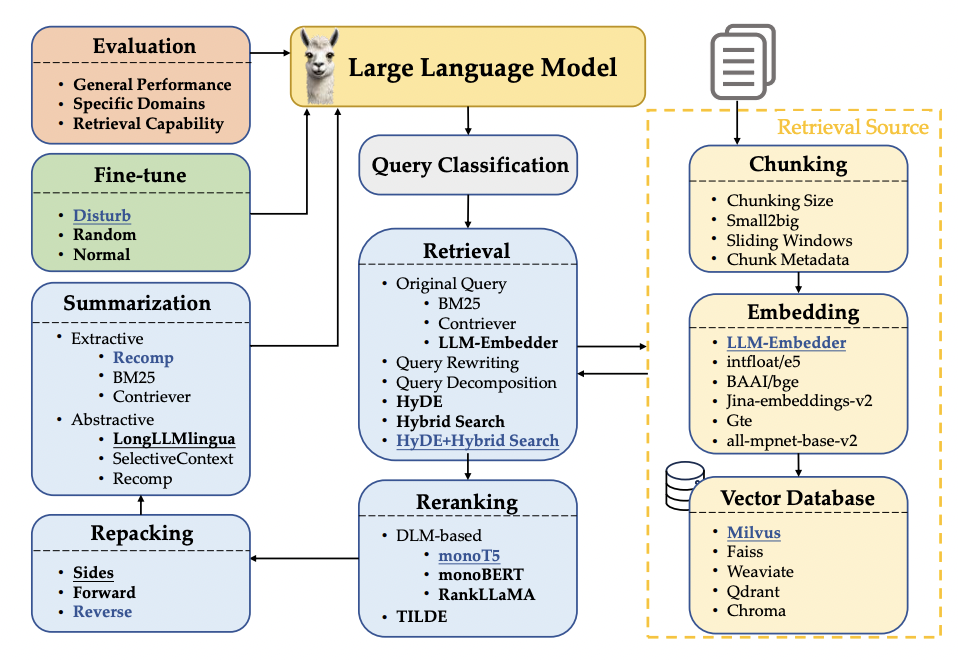
Related Work
Query and Retrieval Transformation
Effective retrieval necessitates accurate, clear, and detailed queries. Even when queries are converted into embeddings, semantic differences between queries and relevant documents can persist.
Previous research has explored methods to enhance query information through transformation techniques, thereby improving retrieval performance. For example:
- Query2Doc and HyDE generate pseudo-documents from original queries to enhance retrieval accuracy.
- Techniques such as Tree of Clarifications decomposes queries into subqueries, aggregating the retrieved content for final results.
- Techniques such as hierarchical prompt summarization and the use of abstractive compressors reduce context length and remove redundancies, further refining the retrieved information.
Retriever Enhancement Strategy
The methods used for document chunking and embedding significantly impact retrieval performance. Common chunking strategies involve dividing documents into smaller segments, but determining the optimal chunk length can be challenging.
- Small chunks may fragment sentences, reducing context coherence.
- Large chunks might include irrelevant information.
Techniques like Small2Big and sliding window chunking maintain context while ensuring relevant information retrieval. Additionally, reranking is necessary to filter out irrelevant documents, with deep language models like BERT, T5, and LLaMA commonly used to improve performance. TILDE achieves efficiency by precomputing and storing the likelihood of query terms, ranking documents based on their sum.
Retriever and Generator Fine-tuning
Fine-tuning both retrievers and generators within the RAG framework is crucial for optimizing performance. Some research focuses on fine-tuning the generator to better utilize retriever context, ensuring faithful and robust content generation.
Examples:
- RAFT: Adapting Language Model to Domain Specific RAG
- SAIL: Search-Augmented Instruction Learning
- ChatQA: Surpassing GPT-4 on Conversational QA and RAG
Others fine-tune the retriever to retrieve beneficial passages for the generator. Holistic approaches treat RAG as an integrated system, fine-tuning both retriever and generator together to enhance overall performance, despite the increased complexity and integration challenges.
Examples:
- Atlas: Few-shot Learning with Retrieval Augmented Language Models
- ARL2: Aligning Retrievers for Black-box Large Language Models via Self-guided Adaptive Relevance Labeling
- REPLUG: Retrieval-Augmented Black-Box Language Models
This study explores the optimal implementation of RAG through modular design and extensive experimentation.
RAG Workflow
Query Classification
Not all queries require retrieval-augmented responses due to the inherent capabilities of LLMs. While RAG can enhance information accuracy and reduce hallucinations, frequent retrieval can increase response time.
Therefore, it is essential to classify queries to determine the necessity of retrieval. Queries requiring retrieval proceed through RAG modules, while others are handled directly by LLMs.
Retrieval is recommended when knowledge beyond the model’s parameters is needed, varying by task. For example, an LLM trained up to 2023 can handle a translation request without retrieval but would require retrieval for an introduction to a new topic.
Chunking
Chunking documents into smaller segments is crucial for enhancing retrieval precision and avoiding length issues in LLMs. This process can be applied at various levels of granularity, such as token, sentence, and semantic levels.
- Token-level chunking is straightforward but may split sentences, affecting retrieval quality.
- Semantic-level chunking uses LLMs to determine breakpoints, preserving context but is time-consuming.
- Sentence-level chunking balances preserving text semantics with simplicity and efficiency.
This study uses sentence-level chunking, examining chunk size from four dimensions: faithfulness, relevancy, retrieval precision, and process time.
Embedding Model Selection
Choosing the right embedding model is crucial for effective semantic matching of queries and chunk blocks. The LLM-Embedder model is used for its balance of performance and size, achieving comparable results with BAAI/bge-large-en but with a smaller size.
Enhancing chunk blocks with metadata like titles, keywords, and hypothetical questions improves retrieval, providing more ways to post-process retrieved texts and helping LLMs better understand the retrieved information.
Vector Databases
Vector databases store embedding vectors with their metadata, enabling efficient retrieval of documents relevant to queries through various indexing and approximate nearest neighbor (ANN) methods.
Criteria for selecting a vector database include:
- Multiple index types
- Billion-scale vector support
- Hybrid search
- Cloud-native capabilities
These criteria impact flexibility, scalability, and ease of deployment in modern, cloud-based infrastructures. Milvus stands out as the most comprehensive solution among evaluated databases, meeting all essential criteria and outperforming other open-source options.
Retrieval Methods
Given a user query, the retrieval module selects the top-k relevant documents from a pre-built corpus based on the similarity between the query and the documents. The generation model then uses these documents to formulate an appropriate response.
Original queries often underperform due to poor expression and lack of semantic information. To address these issues, this study evaluates three query transformation methods using the LLM-Embedder as the query and document encoder:
- Query rewriting
- Query decomposition
- Pseudo-documents generation
Combining lexical-based search with vector search significantly enhances performance.
Reranking Methods
After the initial retrieval, a reranking phase is employed to enhance the relevance of the retrieved documents, ensuring that the most pertinent information appears at the top of the list. This phase uses more precise and time-intensive methods to reorder documents effectively, increasing the similarity between the query and the top-ranked documents.
Approaches include:
- DLM Reranking: Leveraging deep language models for reranking.
- TILDE Reranking: Focusing on query likelihoods.
Reranking significantly improves the quality of generated responses.
Document Repacking
The performance of subsequent processes, such as LLM response generation, may be affected by the order documents are provided. To address this issue, a compact repacking module is incorporated into the workflow after reranking, featuring three repacking methods:
- Forward: Repacks documents by descending relevancy scores from the reranking phase.
- Reverse: Arranges documents in ascending order.
- Sides: Inspired by studies suggesting that optimal performance is achieved when relevant information is placed at the head or tail of the input.
Summarization
Retrieval results may contain redundant or unnecessary information, potentially preventing LLMs from generating accurate responses. Additionally, long prompts can slow down the inference process.
Therefore, efficient methods to summarize retrieved documents are crucial in the RAG pipeline. Summarization tasks can be extractive or abstractive:
- Extractive methods segment text into sentences, then score and rank them based on importance.
- Abstractive compressors synthesize information from multiple documents to rephrase and generate a cohesive summary.
This paper focuses on query-based summarization methods, such as Recomp and LongLLMLingua.
Generator Fine-tuning
In this section, the focus is on fine-tuning the generator while leaving retriever fine-tuning for future exploration. The study aims to investigate the impact of fine-tuning, particularly the influence of relevant or irrelevant contexts on the generator’s performance.
The fine-tuning loss of the generator is the negative log-likelihood of the ground-truth output. Various compositions of contexts, such as relevant documents, randomly sampled documents, and a mix of both, are used to train the model.
The results suggest that mixing relevant and random contexts during training can enhance the generator’s robustness to irrelevant information while ensuring effective utilization of relevant contexts.
Searching for Best RAG Practices
Comprehensive Evaluation
Extensive experiments across various NLP tasks and datasets assess the performance of RAG systems. The tasks include:
- Commonsense reasoning
- Fact-checking
- Open-domain QA
- Multihop QA
- Medical QA
Evaluation metrics cover faithfulness, context relevancy, answer relevancy, and correctness as recommended in RAGAs.
The study uses accuracy as the evaluation metric for commonsense reasoning, fact-checking, and medical QA. For open-domain QA and multihop QA, token-level F1 score and exact match (EM) score are employed. The final RAG score is calculated by averaging the aforementioned five RAG capabilities.
Results and Analysis
Key insights from experimental results include:
- Query Classification Module: Enhances accuracy and reduces latency, improving the overall score and reducing response time.
- Retrieval Module: "Hybrid with HyDE" method achieves the highest RAG score but has high latency. The "Hybrid" or "Original" methods are recommended for reducing latency while maintaining comparable performance.
- Reranking Module: The absence of a reranking module leads to a noticeable drop in performance, highlighting its necessity. MonoT5 achieves the highest average score, affirming its efficacy in augmenting the relevance of retrieved documents.
- Repacking Module: The reverse configuration exhibits superior performance, positioning more relevant context closer to the query.
- Summarization Module: Recomp demonstrates superior performance, addressing the generator’s maximum length constraints effectively. Removing summarization can reduce response time in time-sensitive applications.
Best Practices for Implementing RAG
Best Performance Practice
To achieve the highest performance, it is recommended to:
- Incorporate the query classification module.
- Use the “Hybrid with HyDE” method for retrieval.
- Employ monoT5 for reranking.
- Opt for Reverse for repacking.
- Leverage Recomp for summarization.
This configuration yields the highest average score, although it is computationally intensive.
Balanced Efficiency Practice
To balance performance and efficiency, it is recommended to:
- Incorporate the query classification module.
- Implement the Hybrid method for retrieval.
- Use TILDEv2 for reranking.
- Opt for Reverse for repacking.
- Employ Recomp for summarization.
Since the retrieval module accounts for the majority of processing time, transitioning to the Hybrid method while keeping other modules unchanged can substantially reduce latency while preserving comparable performance.
Multimodal Extension
RAG extends to multimodal applications by incorporating text-to-image and image-to-text retrieval capabilities. This extension involves using a substantial collection of paired image and textual descriptions as a retrieval source.
The text-to-image capability speeds up the image generation process when a user query aligns well with the textual descriptions of stored images, while the image-to-text functionality comes into play when a user provides an image and engages in conversation about it.
These multimodal RAG capabilities offer advantages such as:
- Groundedness: Retrieval methods provide information from verified multimodal materials, ensuring authenticity and specificity.
- Efficiency: Retrieval methods are typically more efficient, especially when the answer already exists in stored materials.
- Maintainability: Retrieval-based methods can be improved by enlarging the size and enhancing the quality of retrieval sources.
Future work includes broadening this strategy to other modalities such as video and speech while exploring efficient and effective cross-modal retrieval techniques.
Conclusion
This study aims to identify optimal practices for implementing retrieval-augmented generation (RAG) to improve the quality and reliability of content produced by large language models. By systematically assessing a range of potential solutions for each module within the RAG framework, the study recommends the most effective approach for each module.
Furthermore, it introduces a comprehensive evaluation benchmark for RAG systems and conducts extensive experiments to determine the best practices among various alternatives. The findings contribute to a deeper understanding of RAG systems and establish a foundation for future research.
Limitations
Evaluating the impact of various methods for fine-tuning LLM generators is crucial. Future exploration includes joint training of retriever and generator and investigating different chunking techniques. Expanding RAG applications to other modalities like speech and video presents an enticing avenue for further research.
Read the full paper on "Searching for Best Practices in Retrieval-Augmented Generation" by Wang et al. for a detailed exploration of optimal practices for implementing RAG.